- Authors

- Name
- 오늘의 바이브
Claude한테 코딩시키고 Codex한테 리뷰 맡겼더니
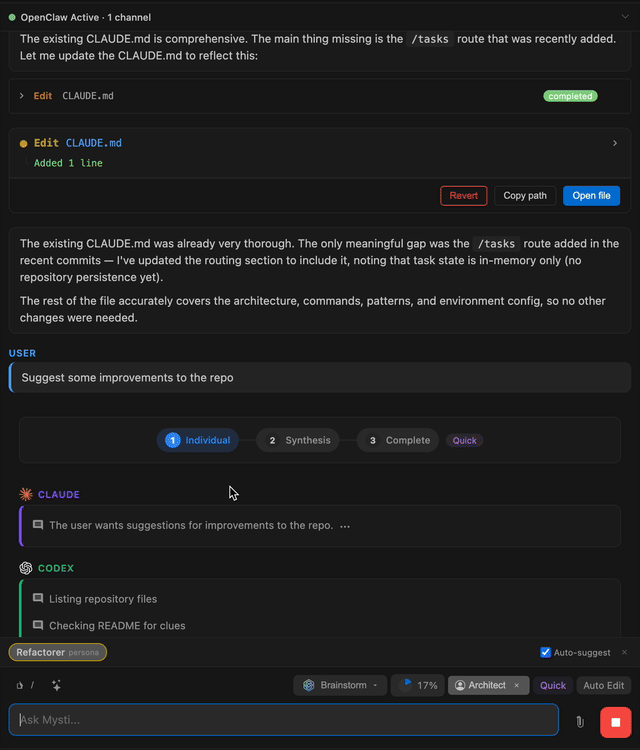
개발자 Baha Abunojaim은 Claude Pro, ChatGPT Plus, Gemini Advanced를 전부 결제하고 있었다. 문제는 한 번에 하나만 쓸 수 있다는 것이었다. Claude에게 코드를 짜게 하고, 그 결과를 복사해서 Codex에 붙여넣고, 다시 Gemini에게 검증을 맡기는 삼중 노동. 컨텍스트를 옮길 때마다 설명을 처음부터 다시 해야 했다.
그래서 직접 만들었다. Mysti라는 이름의 VS Code 확장 프로그램이다. AI 에이전트 여러 마리를 하나의 인터페이스 안에서 동시에 돌리고, 서로 토론까지 시킬 수 있다. 2026년 2월 Hacker News에 올라오자마자 979개의 GitHub 스타를 찍었다. 댓글에서는 "멀티에이전트 협업이 미래"라는 낙관론과 "벤치마크 없이는 AI 점성술"이라는 냉소가 동시에 터졌다.
7개 AI를 한 채팅창에 몰아넣다
Mysti가 지원하는 AI 에이전트는 7개다. 각각의 CLI 도구를 VS Code 안에서 하나의 통합 인터페이스로 묶었다.
| AI 에이전트 | 특기 | CLI 도구 |
|---|---|---|
| Claude Code | 깊은 추론, 복잡한 리팩토링 | claude-code |
| Codex (OpenAI) | 빠른 반복, 익숙한 스타일 | codex-cli |
| Gemini (Google) | 빠른 응답, 긴 컨텍스트 | gemini-cli |
| GitHub Copilot | 멀티모델 접근 | copilot-cli |
| Cline | Plan/Act 모드, 구조화된 태스크 | cline |
| Cursor | 자동 모델 선택 | cursor |
| OpenClaw | WebSocket 스트리밍, 설정 가능한 사고 | openclaw |
핵심은 컨텍스트 공유다. 모든 에이전트가 같은 프로젝트 컨텍스트를 동시에 본다. Claude에게 코드를 짜게 한 뒤 Codex에게 리뷰를 맡길 때, 프로젝트 구조나 이전 대화를 다시 설명할 필요가 없다. @claude 코드 작성해, 그다음 @codex 최적화해처럼 체이닝도 된다.
브레인스톰 모드: AI끼리 싸우게 만드는 전략
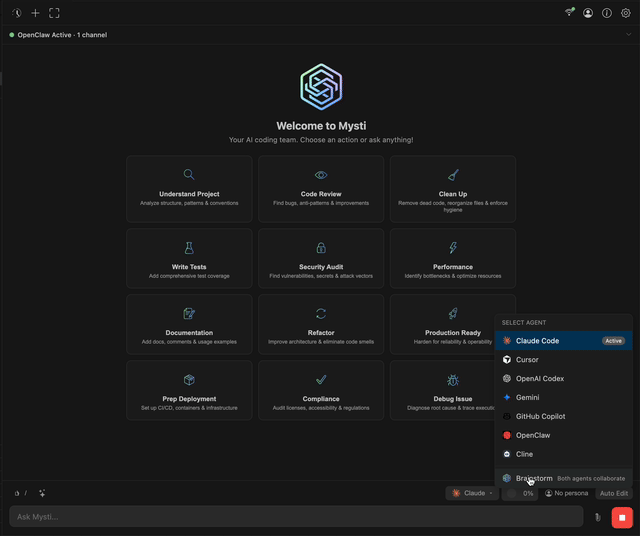
Mysti의 가장 파격적인 기능은 브레인스톰 모드다. 두 개의 AI 에이전트를 골라서 하나의 문제를 놓고 토론시킨다. 전략은 5가지다.
Quick 전략은 단순한 태스크에 쓴다. 한 에이전트가 분석하고 다른 에이전트가 바로 종합한다. 시간이 없을 때 빠른 합의를 끌어내는 방식이다.
Debate 전략이 진짜 재미있다. 한쪽을 비평가(Critic)로, 다른 쪽을 옹호자(Defender)로 세운다. 아키텍처 결정처럼 정답이 없는 문제에서 양쪽의 논리를 부딪히게 한다. 에이전트들이 합의에 도달하면 자동으로 수렴 감지(convergence detection)가 작동해서 토론을 종료한다.
Red-Team 전략은 보안 리뷰에 최적화됐다. 한쪽이 제안하면 다른 쪽이 공격한다. Perspectives 전략은 리스크 분석가와 혁신가의 시점으로 설계를 검토한다. Delphi 전략은 퍼실리테이터와 정제자를 두어 점진적 합의를 만들어간다.
실제로 한 개발자는 Taichi 커널 최적화에서 막혀 있었는데, 두 에이전트를 토론시켰더니 해결됐다고 보고했다. "몇 시간을 절약했다"는 게 그의 평가다.
16개 페르소나와 12개 스킬
Mysti는 AI에게 단순히 코드를 짜라고 시키지 않는다. 16개의 개발자 페르소나를 부여할 수 있다. Architect, Debugger, Security-Minded, Performance Tuner, Prototyper, Refactorer, Full-Stack, DevOps 등이다. 페르소나를 바꾸면 같은 질문에도 완전히 다른 관점의 답이 나온다.
여기에 12개의 토글형 스킬이 더해진다. Concise(간결하게), Test-Driven(테스트 우선), Auto-Commit(자동 커밋), First Principles(원리부터), Scope Discipline(범위 제한) 같은 행동 수정자를 켜고 끌 수 있다.
비평가들은 페르소나가 "무의미하거나 오히려 해롭다"고 반박했다. 하지만 찬성론자의 반론도 날카롭다. "컨텍스트를 큐레이팅하고 규칙을 지정하는 순간, 이미 페르소나를 부여한 것이다." 프롬프트 엔지니어링의 본질이 결국 역할 지정이라는 주장이다.
자율 모드와 세 단계 안전장치
Mysti에는 **자율 모드(Autonomous Mode)**가 있다. AI가 사람의 승인 없이도 스스로 코드를 수정하고 실행하는 모드다. 위험하다. 그래서 세 단계의 안전 레벨을 뒀다.
| 레벨 | 이름 | 동작 |
|---|---|---|
| 1 | Conservative | 모든 변경에 승인 필요 |
| 2 | Balanced | 안전한 작업은 자동, 위험한 작업은 승인 |
| 3 | Aggressive | 대부분 자동 실행, 차단 목록만 제한 |
안전 분류기(safety classifier)가 각 작업을 safe/caution/blocked로 분류한다. 모든 자율 결정은 감사 로그(audit trail)에 기록된다. 학습 메모리가 사용자 패턴에 적응해서 시간이 지날수록 정확도가 올라가는 구조다.
여기에 접근 제어도 별도로 존재한다. Read-only(읽기만), Ask-permission(매번 승인), Full-access(자율 실행)의 3단계다. 자율 모드와 접근 제어를 조합하면 상당히 세밀한 권한 설정이 가능하다.
Hacker News의 반응: 점성술인가, 미래인가
Mysti에 대한 Hacker News 커뮤니티의 반응은 정확히 반으로 갈렸다.
낙관론 진영의 핵심 논거는 크로스 검증이다. 한 모델이 만든 버그를 같은 모델에게 다시 보여주면 잘 못 찾는다. 하지만 다른 모델에게 보여주면 즉시 발견한다는 것이다. "Claude에게 개발시키고 Codex에게 커밋 전 리뷰를 맡기면 높은 가치의 코드가 나온다"는 현장 보고가 여러 건 올라왔다.
비관론 진영의 핵심 논거는 측정 부재다. 한 연구자가 인용한 논문에 따르면, 단일 에이전트의 기준 성능이 약 45%를 넘으면 멀티에이전트 협업의 수익률이 급격히 떨어지거나 오히려 마이너스가 된다. "실제로 측정하지 않으면 우리가 하는 건 AI 점성술"이라는 독설이 이 진영의 대표 발언이다.
비용 문제도 나왔다. 여러 모델을 동시에 돌리면 토큰 사용량이 3배로 뛸 수 있다. 개발자 Baha는 컨텍스트 최적화로 약 80%의 오버헤드를 줄일 수 있다고 응답했지만, 구체적인 수치는 아직 없다.
컨텍스트 압축이라는 숨은 기술
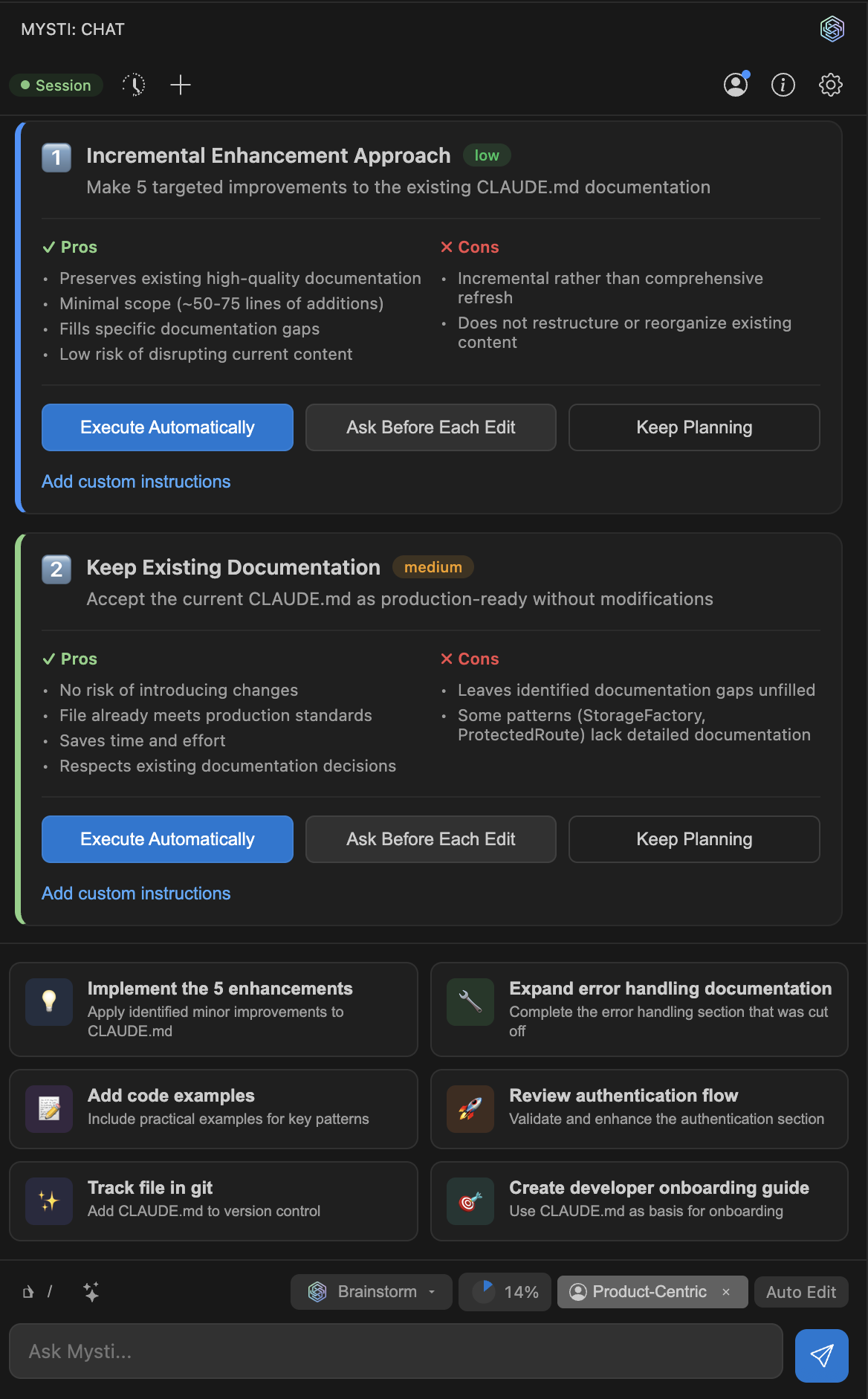
멀티에이전트 시스템의 가장 큰 병목은 컨텍스트 윈도우다. 여러 에이전트가 대화할수록 토큰이 쌓이고, 한계에 도달하면 시스템이 멈춘다. Mysti는 이 문제를 **컨텍스트 압축(Context Compaction)**으로 해결했다.
Claude Code의 경우 네이티브 /compact 명령을 지원한다. 다른 프로바이더에서는 클라이언트 사이드 요약을 수행한다. 각 패널마다 독립적으로 토큰 사용량을 추적하며, 75% 임계값에 도달하면 자동으로 압축이 트리거된다.
Gemini의 긴 컨텍스트 윈도우를 활용하는 전략도 눈에 띈다. Hacker News 댓글 중 하나는 Gemini를 "프로젝트 철학을 추적하는 장기 관찰자"로 활용한다고 밝혔다. Claude가 코드를 짜고, Codex가 리뷰하는 동안, Gemini가 전체 프로젝트의 방향성과 일관성을 감시하는 삼각 편대 구성이다.
이 구조에서 지능형 플랜 감지(Intelligent Plan Detection) 기능도 중요하다. 에이전트가 여러 구현 방식을 제안하면 자동으로 감지해서 사용자에게 선택지를 보여준다. 사람이 최종 결정권을 쥐되, AI가 선택지를 구조화해주는 방식이다.
페어 프로그래밍의 확장인가, 비용의 낭비인가
Mysti의 접근 방식은 결국 페어 프로그래밍의 AI 버전이다. 사람 두 명이 한 화면 앞에 앉아서 코드를 짜는 것처럼, AI 두 마리가 한 문제를 놓고 서로 견제하며 코드를 짠다. 차이점은 AI 파트너가 절대 지치지 않고, 감정적으로 반발하지 않으며, 관점을 자유롭게 전환할 수 있다는 것이다.
하지만 근본적인 질문이 남는다. 모델 A의 출력을 모델 B에게 검증시키는 것이 진짜 '토론'인가, 아니면 그냥 추가 API 호출인가. 현재까지 이 질문에 대한 엄밀한 답은 없다. Baha 본인도 공식 벤치마크는 아직 없다고 인정했다. 있는 것은 "몇 시간을 절약했다", "높은 가치의 코드가 나왔다"는 개발자들의 증언뿐이다.
그럼에도 Mysti가 보여주는 방향 자체는 주목할 만하다. AI 코딩 도구의 경쟁이 '어떤 모델이 가장 똑똑한가'에서 '여러 모델을 어떻게 조합하는가'로 이동하고 있다는 신호다. 단일 모델의 한계를 인정하고, 다양성에서 답을 찾으려는 시도. 그것이 점성술인지 과학인지는 벤치마크가 나와봐야 알겠지만, 적어도 979명의 개발자가 별을 찍을 만큼의 가능성은 있다.