- Authors

- Name
- 오늘의 바이브
The Copy-Paste Workflow Nobody Talks About
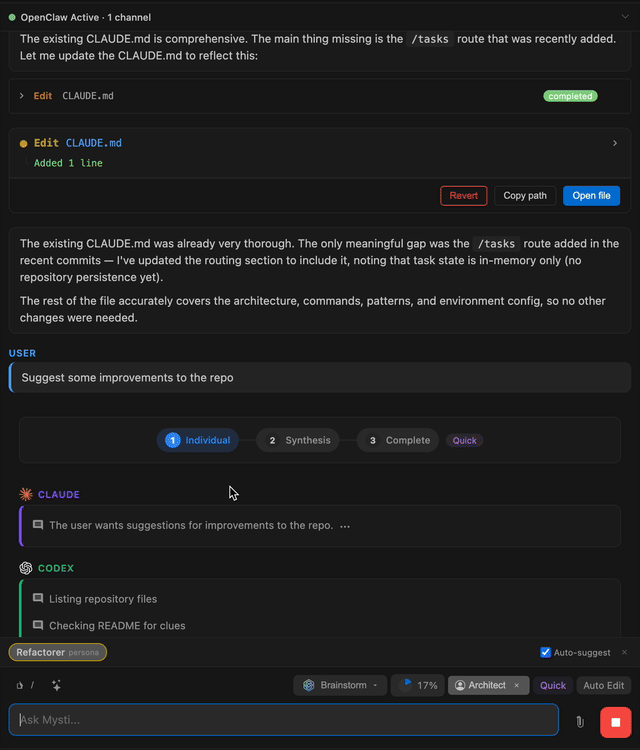
Developer Baha Abunojaim was paying for Claude Pro, ChatGPT Plus, and Gemini Advanced simultaneously. The problem was that he could only use one at a time. Write code with Claude, copy the output, paste it into Codex, re-explain the entire project context, then do the same with Gemini for verification. Three subscriptions, triple the manual labor.
So he built Mysti, a VS Code extension that puts multiple AI coding agents in the same interface and lets them talk to each other. It hit Hacker News in February 2026 and racked up 979 GitHub stars. The comments section became a battleground between developers who called multi-agent collaboration "quite likely the future" and skeptics who said "without actually measuring it all we're doing is AI astrology."
Both sides have a point.
Seven AI Agents, One Chat Window
Mysti supports seven AI providers. Each one connects through its respective CLI tool, wrapped into a unified VS Code interface.
| AI Agent | Strength | CLI Tool |
|---|---|---|
| Claude Code | Deep reasoning, complex refactors | claude-code |
| Codex (OpenAI) | Fast iteration, familiar style | codex-cli |
| Gemini (Google) | Fast responses, long context | gemini-cli |
| GitHub Copilot | Multi-model access | copilot-cli |
| Cline | Plan/Act mode, structured tasks | cline |
| Cursor | Auto model selection | cursor |
| OpenClaw | WebSocket streaming, configurable thinking | openclaw |
The key feature is shared context. All agents see the same project state simultaneously. When Claude writes code and Codex reviews it, there is no need to re-explain the project structure or prior conversation. You can chain tasks inline: @claude Write tests, then @codex optimize them. The context carries over automatically.
Brainstorm Mode: Making AIs Fight Each Other
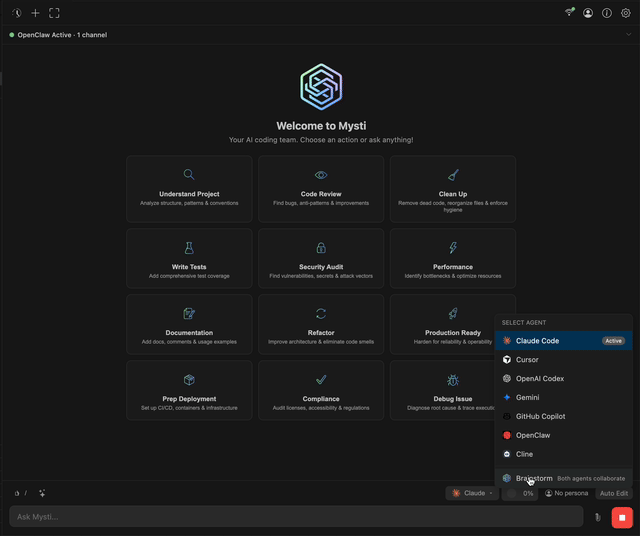
The most aggressive feature in Mysti is Brainstorm Mode. You pick two AI agents, give them a problem, and let them debate. There are five strategies.
Quick is for simple tasks. One agent analyzes, the other synthesizes. Done in a single round.
Debate is where things get interesting. One agent plays the Critic, the other plays the Defender. It works well for architecture decisions where there is no single right answer. When the agents reach agreement, convergence detection kicks in and ends the discussion automatically.
Red-Team is built for security review. One agent proposes, the other attacks. Perspectives pits a Risk Analyst against an Innovator for design decisions. Delphi uses a Facilitator and Refiner for gradual consensus-building.
One developer reported being stuck on Taichi kernel optimization for hours. They put two agents into Debate mode and the problem was solved. Their review: "It saved me several hours."
16 Personas and 12 Toggleable Skills
Mysti does not just throw code at an AI and hope for the best. It assigns 16 developer personas that shape how each agent thinks: Architect, Debugger, Security-Minded, Performance Tuner, Prototyper, Refactorer, Full-Stack, DevOps, and eight more. Switch the persona and the same prompt produces fundamentally different output.
On top of that, there are 12 toggleable skills acting as behavioral modifiers: Concise, Test-Driven, Auto-Commit, First Principles, Scope Discipline, and seven others. You can stack them in any combination.
Critics on Hacker News argued that persona assignment is "somewhere between pointless and actively harmful." The counterargument was sharp: "By curating context and designating rules, you're assigning it a persona whether you call it that or not." Prompt engineering is role assignment. The only question is whether you do it deliberately or accidentally.
Autonomous Mode and Its Three Safety Levels
Mysti includes an Autonomous Mode where agents modify and execute code without human approval for each action. This is inherently dangerous. The tool addresses it with three safety levels.
| Level | Name | Behavior |
|---|---|---|
| 1 | Conservative | Every change requires approval |
| 2 | Balanced | Safe operations auto-execute, risky ones need approval |
| 3 | Aggressive | Most operations auto-execute, only blocked actions restricted |
A safety classifier categorizes each action as safe, caution, or blocked. Every autonomous decision gets logged to an audit trail. A learning memory system adapts to user patterns over time, improving classification accuracy.
There is a separate access control layer on top: Read-only, Ask-permission, and Full-access. Combined with the autonomy levels, this creates a granular permission matrix. Whether developers will actually use anything beyond the default conservative settings remains to be seen.
Hacker News: The Optimists and the Skeptics
The Hacker News reception was split almost exactly in half.
The optimist camp rallied around cross-validation. When one model introduces a bug, that same model struggles to find it. But a different model spots it immediately. Multiple developers reported that "asking Claude to develop and Codex to review the uncommitted changes will typically result in high-value code." The logic is straightforward: different training data produces different blind spots, so combining models patches each other's weaknesses.
The skeptic camp focused on measurement. A researcher cited a paper showing that "coordination yields diminishing or negative returns once single-agent baselines exceed ~45%." In other words, once a single AI is good enough, adding more AI might actually make things worse. "Without actually measuring it all we're doing is AI astrology" became the thread's sharpest one-liner.
Cost was another concern. Running multiple models simultaneously can triple your token usage. Baha responded that context optimization could reduce the overhead by roughly 80%, but concrete benchmarks are still missing.
The Hidden Engineering: Context Compaction
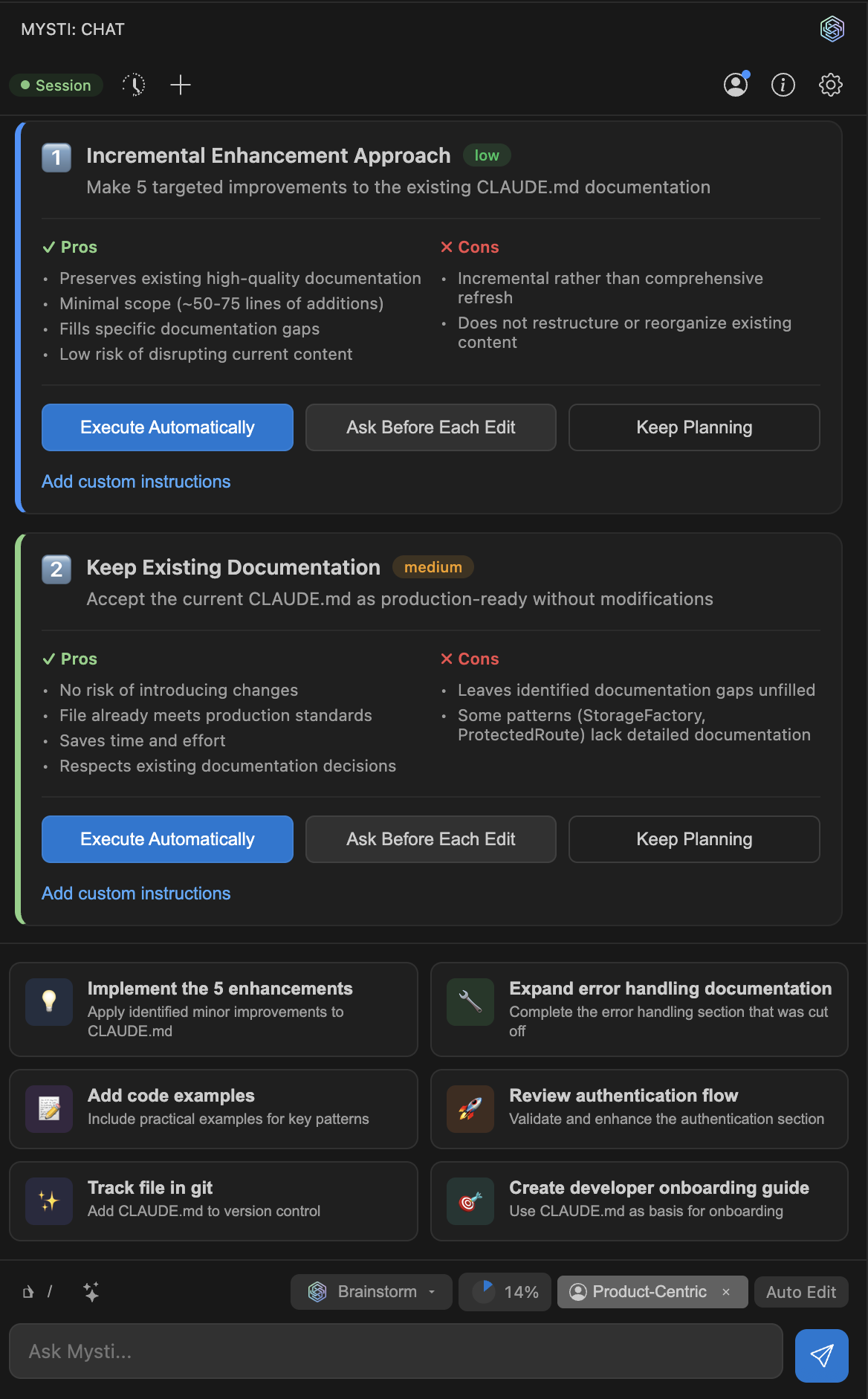
The biggest bottleneck in any multi-agent system is the context window. More agents talking means more tokens consumed. Hit the limit and everything grinds to a halt. Mysti tackles this with Context Compaction.
For Claude Code, it leverages the native /compact command. For other providers, it performs client-side summarization. Each panel tracks token usage independently, and compression triggers automatically at 75% capacity.
One Hacker News commenter described using Gemini as a "long-term observer" that tracks project philosophy while Claude writes code and Codex reviews it. It is a three-way formation: one builds, one critiques, one watches the big picture. This plays to each model's strengths. Gemini's massive context window makes it ideal for maintaining awareness of an entire codebase, while Claude and Codex handle the line-by-line work.
The Intelligent Plan Detection feature also deserves attention. When agents propose multiple implementation approaches, Mysti auto-detects them and presents structured choices to the user. The human retains final decision authority, but the AI organizes the option space.
Pair Programming, Scaled Beyond Humans
Mysti is fundamentally an AI-powered extension of pair programming. Two humans sit at one screen, catch each other's mistakes, and produce better code through constant feedback. Now replace the humans with AI agents that never get tired, never get defensive, and can switch perspectives on command.
But the core question lingers. Is routing Model A's output through Model B a genuine "debate," or just an extra API call with extra cost? There is no rigorous answer yet. Baha acknowledged the absence of formal benchmarks. All that exists are developer testimonials about saved hours and higher-quality code.
Still, the direction Mysti points toward matters. The AI coding tool competition is shifting from "which model is smartest" to "how do you orchestrate multiple models." It is an acknowledgment that no single model gets everything right. Whether that insight leads to measurable gains or just fancier workflows, 979 developers thought it was worth a star. The benchmarks will eventually tell us if they were right.