- Authors

- Name
- 오늘의 바이브
6,000 Files, 112 Reports, 2 Weeks
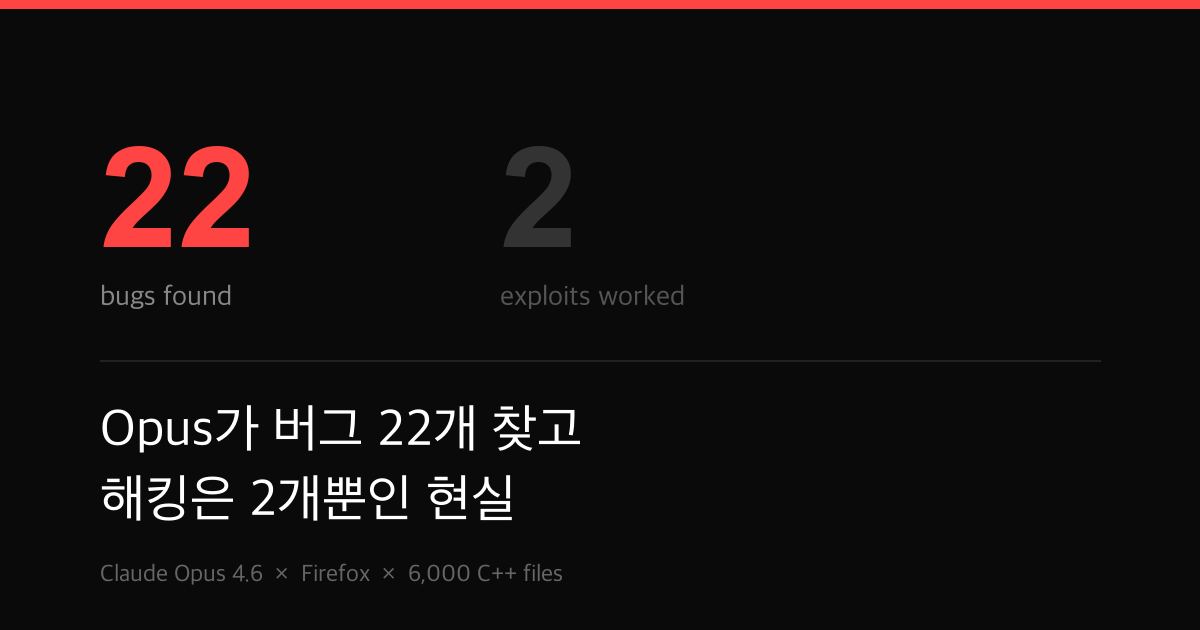
In January 2026, Anthropic pointed its latest model, Claude Opus 4.6, at the Firefox codebase. It scanned roughly 6,000 C++ files and submitted 112 unique reports over a two-week period. Mozilla confirmed 22 of those as new security vulnerabilities.
That wasn't all. Beyond the security issues, Mozilla confirmed 90 additional bugs discovered through the AI-assisted analysis. These were assertion failures and logic error classes that traditional fuzzing had missed entirely. The way an LLM reads code is fundamentally different from how automated tooling does it, and this is the proof.
14 High-Severity Bugs in Two Weeks
Here's the severity breakdown of those 22 vulnerabilities:
| Severity | Count |
|---|---|
| High | 14 |
| Moderate | 7 |
| Low | 1 |
According to Anthropic, those 14 high-severity bugs represent "almost a fifth" of all high-severity vulnerabilities patched in Firefox during 2025. One AI model, two weeks of scanning, and it matched roughly 20% of what security teams found over an entire year.
Most of these vulnerabilities were patched in Firefox 148, released in late February 2026. The security advisory is tracked as MFSA2026-13. The remaining issues are scheduled for upcoming releases.
CVE-2026-2796: A 9.8 CVSS Monster
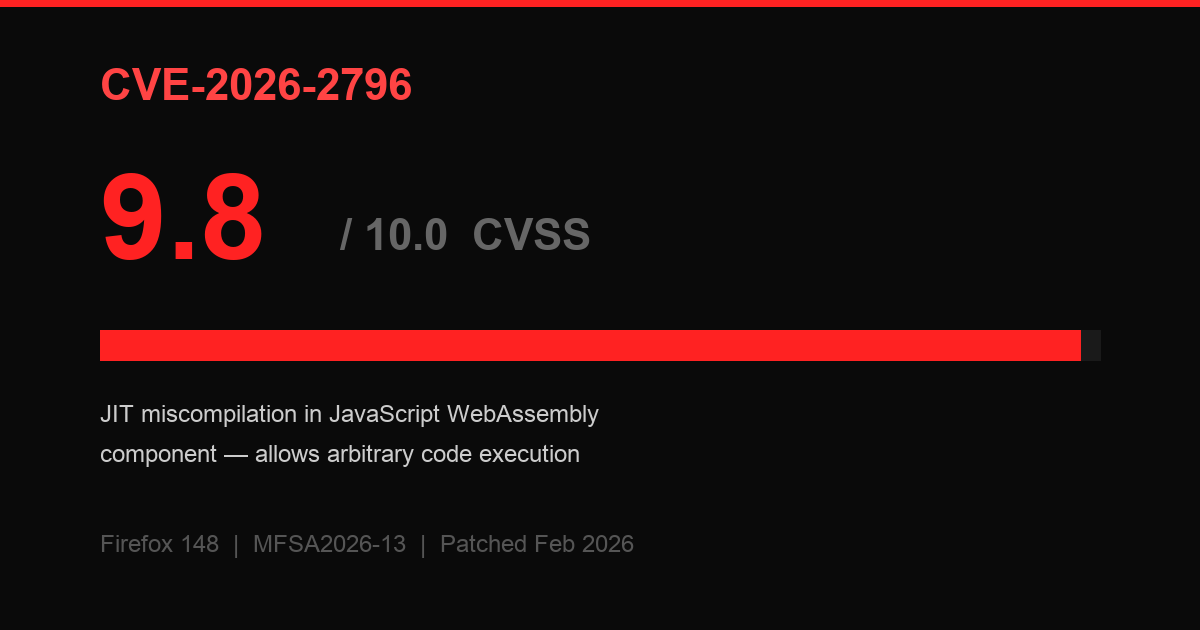
The most severe finding was CVE-2026-2796, a JIT miscompilation bug in the JavaScript WebAssembly component. It scored 9.8 on the CVSS scale. Out of 10. That's effectively the highest risk rating a vulnerability can get.
JIT compiler bugs are particularly dangerous. JIT compilers translate JavaScript to machine code at runtime. When that compilation goes wrong, it can open a path for attackers to directly manipulate memory and execute arbitrary code in the browser.
Another notable discovery was a use-after-free bug in Firefox's JavaScript engine. Claude found it just 20 minutes into its exploration. Use-after-free vulnerabilities -- where freed memory gets accessed again -- are a classic entry point for browser exploitation. The kind of bug that takes human security researchers hours or days of code auditing. AI did it in 20 minutes.
Great at Finding, Terrible at Exploiting
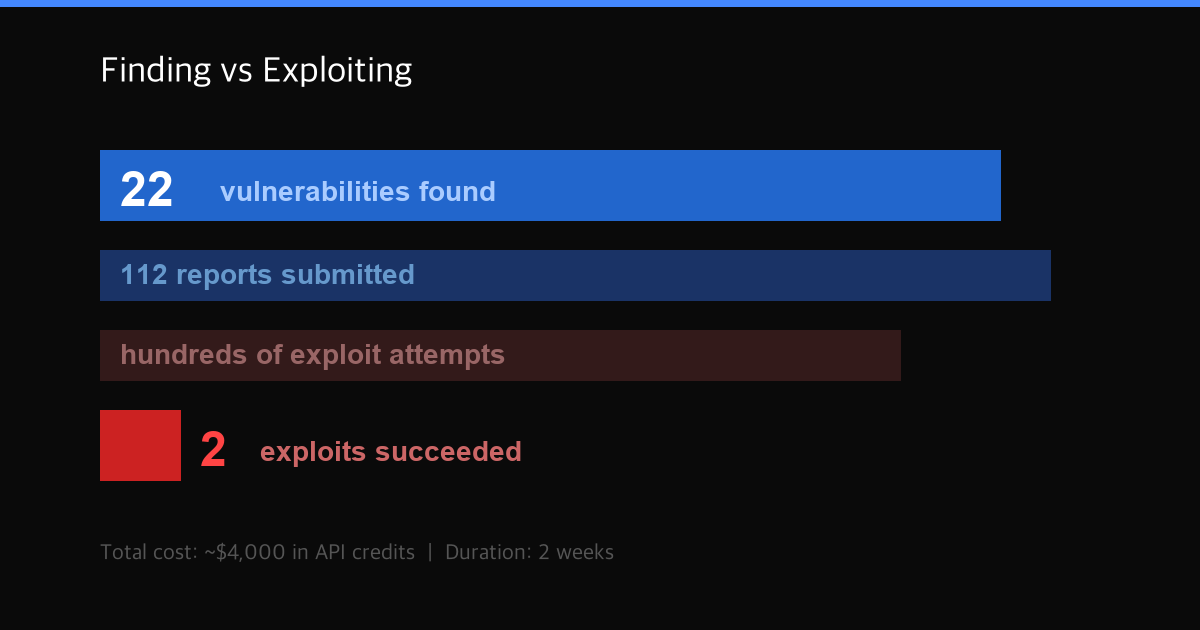
Here's where this research gets interesting. Anthropic didn't just ask Claude to find vulnerabilities. They tasked it with developing working exploits for them. Several hundred attempts were made, costing roughly $4,000 in API credits.
The result was bleak. Out of hundreds of attempts, Claude produced functional exploits in exactly 2 cases. Even those only worked in testing environments where security features like sandboxing had been intentionally stripped out. Against a real production browser, nothing worked.
| Metric | Value |
|---|---|
| C++ files scanned | ~6,000 |
| Reports submitted | 112 |
| Confirmed vulnerabilities | 22 |
| Additional bugs found | 90 |
| Exploit attempts | Hundreds |
| Successful exploits | 2 |
| Total cost | ~$4,000 |
Anthropic acknowledged the asymmetry directly: "The fact that Claude could succeed at automatically developing a crude browser exploit, even if only in a few cases, is concerning." They also noted that identifying vulnerabilities proves far cheaper than creating exploits.
The Defender's Advantage
The message from this research is clear. AI is remarkably efficient at finding bugs. It is remarkably bad at weaponizing them. In security terms, this is the defender's advantage.
There's a large gap between the cost of finding a vulnerability and the cost of turning it into a working exploit. AI is widening that gap in favor of defense. The speed of discovery is accelerating. The speed of exploitation is not keeping pace.
The caveat is the word "yet." Two successes out of hundreds of attempts is a low rate. But it's not zero. Anthropic used the word "concerning" for a reason. As models improve, that success rate could climb.
$4,000 for 20% of a Year's High-Severity Patches
The cost-effectiveness numbers are striking. About $4,000 in API credits produced findings that account for roughly 20% of Firefox's annual high-severity vulnerability patches. All in two weeks.
A senior security researcher in the US earns 250,000 per year. Bug bounty programs pay thousands to tens of thousands of dollars per high-severity finding. At 286 per bug**.
This calculation ignores model development costs, engineering time from Anthropic's team, and infrastructure overhead. But from a marginal cost perspective, AI security auditing operates at a fundamentally different scale than traditional approaches.
Mozilla responded positively: "The scale of findings reflects the power of combining rigorous engineering with new analysis tools."
Where AI Beats Fuzzing and Where It Doesn't
The traditional workhorse of software security testing is fuzzing -- feeding random inputs into a program to trigger crashes. Google's OSS-Fuzz is the canonical example, and it has found thousands of bugs over the years.
What Claude does differently is read the code. It analyzes the logic of 6,000 C++ files, traces data flows, and recognizes patterns that could indicate vulnerabilities. This approach is why it caught assertion failures and logic errors that fuzzing missed.
But AI doesn't replace fuzzing. Fuzzing is execution-based and excels at catching runtime bugs. AI does something closer to static analysis and is better at catching structural vulnerabilities in code. They're complementary. This research shows that AI can cover the blind spots of existing tools, not that it can eliminate them.
What 22 vs 2 Really Means
The most important number in this research isn't 22, or 14, or 9.8. It's 22 versus 2.
The gap between finding and exploiting. AI has likely already surpassed humans at discovering weaknesses in software. No human can scan 6,000 files in two weeks and pull out 14 high-severity bugs. But the ability to turn those discoveries into actual attacks still lags far behind human hackers.
As long as that gap holds, AI is a more useful tool for defense than for offense. But don't forget why Anthropic wrote "concerning." Two isn't zero. There's no guarantee that gap stays wide forever.
What this research proves is one thing: right now, using AI for defense is overwhelmingly advantageous over using it for attack. How fast the software industry moves while this window is open will determine the future of AI security.
Sources